
Zdefiniuj region zainteresowania (ROI)
Dodaj do arkusza narzędzie ViDi Read i zdefiniuj region działania funkcji. Jeśli detal nie jest dokładnie spozycjonowany dodaj lokalizator (fixture), za którym region będzie podążał. Idealny region powinien obejmować na tyle duży obszar, aby za każdym razem ciąg znaków znalazł się w jego zakresie z uwzględnieniem niewielkiego naddatku zachowującego strefę ciszy dookoła napisu. Zawężenie regionu skraca czas segmentacji pojedynczych znaków oraz minimalizuje wpływ mylącego tła.

Ustaw rozmiar spodziewanych znaków
Otwórz ViDi Editor i dodaj zdjęcia do bazy.
Nie przejmuj się na ten moment żółtymi ramkami z etykietami – część znaków nie zostanie wyodrębnionych, część zostanie zidentyfikowana poprawnie, a inne mogą mieć błędne etykiety. Narzędzie ViDi Read posiada predefiniowaną bazę czcionek – próbuje odczytać znaki samodzielnie na ich podstawie. Proces uczenia mamy dopiero przed sobą!

Na początku zdefiniujmy uśrednioną wielkość znaków jakich się spodziewamy. Pomoże to w prawidłowej segmentacji znaków, czyli rozbiciu ciągu na pojedyncze znaki.

Zmienić rozmiar pojedynczego znaku możemy przez dopasowanie rozmiaru szarego prostokąta. Nowy rozmiar od razu aktualizuje się w zakładce Tool Parameters w polu Feature Size.
Nazwij znaki
Rozpocznijmy proces nadawania etykiet poszczególnym znakom. Wybierz ikonę otwartej książki, a program spróbuje odczytać znaki na podstawie predefiniowanych czcionek na wszystkich zdjęciach znajdujących się w bazie. Najpewniej nie wszystko zostanie odczytane, ale usprawnisz sobie pracę mając, chociaż częściowo, dokonaną segmentację.

Zaakceptuj widok obrazu – ramki zmienią swój kolor na zielony – tym kolorem będą oznaczane wszystkie etykiety które nadałeś. Kolor żółty jest zarezerwowany dla odczytu narzędzia ViDi Read. W razie potrzeby dopasowuj prostokąty do znaków, zmieniając ich rozmiar i obracając je, tak aby jak najlepiej je okalały. Następnie popraw błędnie odczytane etykiety. Ten proces jest dość czasochłonny – dla stabilnej pracy głębokie uczenie potrzebuje wielu przykładów. Oczywiście ich ilość zależy od stopnia trudności odczytu – przede wszystkim od tego jak bardzo poszczególne znaki się od siebie różnią. Zdarzają się aplikacje, które działają bez żadnych problemów po wyuczeniu na bazie kilkudziesięciu obrazów – nie jest to jednak zalecane, a oszacowanie ilu zdjęć możemy potrzebować wymaga pewnej wprawy. Lepiej trzymać się zasady: im więcej tym lepiej!


Zdefiniuj swój model
Dwa najczęściej spotykane modele podczas używania narzędzia ViDi Read to model Node i model RegEx. Te dwa modele nie zawsze są wymienne i mogą działać inaczej w zależności od zastosowania.
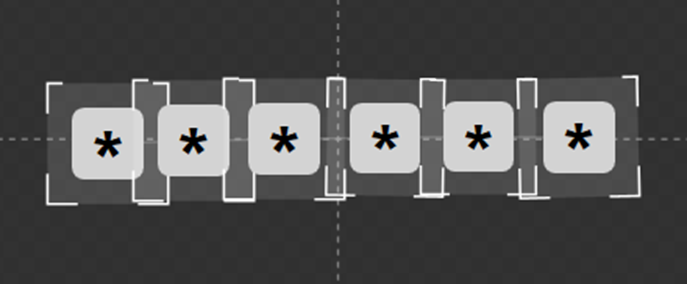
Model Node jest opcją domyślną podczas tworzenia nowego modelu. Model opiera się na zdefiniowaniu wzajemnego położenia pomiędzy kolejnymi znakami zatem może obsługiwać różne wzorce, takie jak zakrzywione ścieżki i wiele linii tekstu. W zakładce Model Editor ustaw tolerancje kąta przekrzywienia, skali, proporcji oraz rozkładu normalnego modelu. Im lepiej znamy wariancje modelu, tym bardziej możemy zawężać obszar jego poszukiwań. Uniwersalność i wysoka skuteczność w trudnych przypadkach modelu Node może wiązać się z dłuższym czasem przetwarzania. Jeśli aplikacja zawiera liniowy tekst w jednym wierszu, użycie modelu RegEx może przyspieszyć przetwarzanie o 70% w porównaniu z modelem Node. Model RegEx opiera się na zdefiniowaniu rodzaju ciągu znaku. W prezentowanym przykładzie byłoby to wskazanie sześciu cyfr. Ostatni model – String definiuje jedynie minimalną liczbę znaków – zastosuj go tylko jeśli twój ciąg znaków jest całkowicie nieprzewidywalny.
Wybierz zestaw testowy zdjęć i dobierz parametry
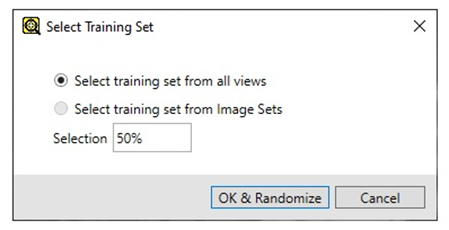
Wybierz zestaw zdjęć których użyjesz do uczenia sieci. Pamiętaj by zostawić część zdjęć do sprawdzenia działania programu! W zakładce Select Training Set wskaż procent obrazów które chcesz wykorzystać do uczenia – zostaną one losowo wybrane z całej puli.
Na tym etapie możesz także dostosować liczbę epok przez które będzie przebiegać procedura optymalizacji. Skorzystaj z tej opcji jeśli odczyt Twojego ciągu nie powoduje większych trudności lub gdy testujesz różne opcje konfiguracji narzędzia – zmniejszenie liczby epok skróci czas nauki. Jeśli próbujesz odczytać bardzo niewyraźny napis spróbuj zwiększyć ten parametr dla poprawy skuteczności.
Przejdź do zakładki Tool Parameters i zastanów się jak zmieniają się twoje zdjęcia. Przykładowo – jeżeli wiesz że kontrast waha się o +- 10 % umieść tę wartość w sekcji perturbacji. Poszerzysz w ten sposób zakres identyfikacji znaku jeśli taki się pojawi!
Do nauki!
Etykiety naniesione? Zdjęcia do nauki wybrane? Ustawienia parametrów gotowe? Jeśli tak, nadszedł czas na proces uczenia narzędzia! Naciśnij przycisk neuronów i czekaj na wyniki. Proces uczenia może zająć kilka minut. Sieci neuronowe to cała masa danych, potrzebujesz wydajnego komputera z wydajnym procesorem GPU (kartą graficzną Nvidia np. RTX 3070).
Sprawdź wyniki
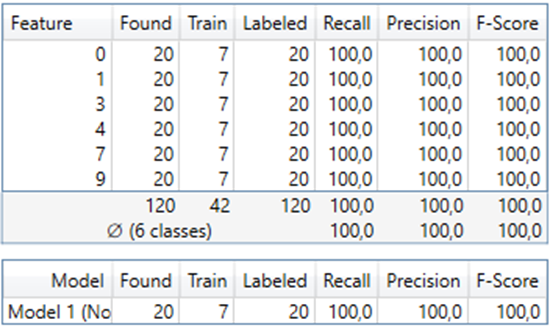
Po zakończeniu procesu uczenia podejrzyj zakładkę Database Overview, znajdziesz tam Confusion Matrix, czyli statystykę przedstawiającą ilość wystąpień poszczególnych znaków i skuteczność twoich sieci. Przeanalizuj wyniki i jeśli któryś ze znaków został błędnie odczytany, dodaj problematyczny obraz do sekcji Training Set i powtórz proces uczenia. Upewnij się także czy nie popełniłeś żadnego błędu podczas etykietowania.

A może da się czytać szybciej?
Aby w pełni wykorzystać możliwości narzędzia, skrócić czas cyklu i zwiększyć wydajność warto czasem wyjść poza konfiguracje domyślne.
– Nie bój się zmieniać gęstości próbkowania
Parametr ten określa, ile próbek obrazu, działając w trybie runtime, zostanie przetworzonych przez narzędzie In-Sight ViDi Read w celu zwrócenia wyniku. Chociaż narzędzie domyślnie ustawia gęstość próbkowania na cztery, zmiana tej liczby może nie mieć wpływu na dokładność aplikacji. Zmniejszenie gęstości próbkowania o jeden może przynieść przyspieszenie o 80% w porównaniu z równoważnym modelem RegEx o gęstości próbkowania równej cztery.
– Ustal zakres rozmiarów znaków
Zakres jest ustawiany automatycznie, aby upewnić się, że wszystkie oczekiwane znaki zostaną uwzględnione. Zachowanie domyślnego zakresu rozmiarów jest przydatne w przypadku różnic w wymiarach czcionek i znaków. Jeśli jednak rozmiar znaków jest powtarzalny, zmniejszenie tolerancji w tym zakresie może przynieść wzrost prędkości o ponad 35%.
Pamiętaj że optymalizacje czasowe oraz wybór modelu muszą być zawsze dopasowane do danej aplikacji. Nie wszystkie z opisanych technik zwiększania wydajności będą miały zastosowanie
w każdej sytuacji, ale każde pojedyncze usprawnienie może przynieść ogromne korzyści w czasie działania aplikacji. Niezależnie od tego, jakie wskazówki zostaną zastosowane, przed wdrożeniem należy zawsze przetestować i sprawdzić wydajność systemu.